
[논문리뷰] A ConvNet for the 2020s, ConvNeXt 리뷰
1. 초록

시각 인식의 '활기찬 20년대'는 비전 트랜스포머(ViT)의 도입으로 시작되었으며, 이는 최첨단 이미지 분류 모델로서 ConvNet을 빠르게 대체했습니다.
반면에 바닐라 ViT는 Object Detection 및 semantic segmentation과 같은 일반적인 컴퓨터 비전 작업에 적용할 때 어려움을 겪습니다.
Hierarchical Transformer(계층형 트랜스포머)(예: Swin Transformer)는 여러 ConvNet 선행 모델을 재도입하여 트랜스포머를 일반 비전 백본으로 실질적으로 사용할 수 있게 하고 다양한 비전 작업에서 놀라운 성능을 보여주었습니다.
그러나 이러한 하이브리드 접근 방식의 효과는 컨볼루션의 내재된 귀납적 편향보다는 트랜스포머의 본질적인 우수성 때문인 경우가 많습니다.
이 논문에서는 설계 공간을 재검토하고 순수한 ConvNet이 달성할 수 있는 한계를 테스트합니다.
또한 비전 트랜스포머 설계를 위해 표준 ResNet을 점진적으로 '현대화'하고, 그 과정에서 성능 차이에 기여하는 몇 가지 핵심 구성 요소를 발견합니다.
이러한 탐구의 결과물이 바로 ConvNeXt라고 불리는 순수 ConvNet 모델입니다.
표준 ConvNet 모듈로만 구성된 ConvNeXt는 정확도와 확장성 측면에서 트랜스포머와 경쟁하여 87.8%의 ImageNet 최고 정확도를 달성하고 COCO 감지 및 ADE20K 세분화에서 스윈 트랜스포머를 능가하는 성능을 발휘하면서도 표준 ConvNet의 단순성과 효율성을 그대로 유지합니다.
2. 소개
2010년대에는 Neural Network 가 크게 발전했으며, 특히 시각 인식 분야에서 사용하는 ConvNet 이 AlexNet, VGGnet, ResNet(ResNeXt), DenseNet, EffientNet,... 등을 거치면서 급격하게 발전했습니다.
그리고 NLP 분야에서는 Transformer 가 등장하고 RNN 구조를 대체하였고, CV 와 NLP 분야의 차이에도 불구하고 ViT(Vision Transformer) 가 등장하면서 비전 분야에도 Transformer 가 쓰이기 시작했습니다.
그런데 ViT 는 ConvNet이 가지는 inductive biases 와 translation equivariance가 없고, $O^{2}$ 시간복잡도를 가지는 많은 연산량 등의 단점 때문에 ViT 는 비전에서 Object Detection 이나 Semantic Segmentation 에 사용을 못하는 등 여러 비전 분야에 사용을 하지 못했습니다. 이를 해결하기 위해 Hierarchical Transformer(계층형 트랜스포머) 가 등장합니다.
Hierarchical Transformer는 ConvNet 쓰이는 “sliding window" 를 재도입함으로서 ConvNet 과 유사하게 작동하게 하여 이를 해결합니다. Swin Transformer 가 그 예로 높은 성능과 다양한 비전 분야에서 백본으로 사용할 수 있었습니다. 이는 Convolution 의 본질은 무의미해지는 것이 아니며 더 필요하다는 것을 보여줍니다.
비전분야에서 Transformer 의 발전은 Convolution 을 되살리는데 초점을 두고 있는데, 비용(필요 연산량) 이나 모델 구조가 더 복잡해지는 등의 문제가 있습니다. 아이러니 하게도 Transfomer 가 없는 순수 ConvNet 은 Convolutioin 의 장점을 대부분 가지며 간단하고 군더더기 없는 구조라는 것이죠.
순수 ConvNet 이 Transformer 에 밀리는 이유는 여러 비전 Task 에서 Transformer 가 더 낫기 때문인데, 이는 Transformer 가 멀티 헤드 셀프 어텐션으로 우수한 scaling behavior 를 가지기 때문입니다.
이 논문에서는 ConvNet 과 Transfomer 의 아키텍쳐를 비교해서 성능 차이를 내는 변수를 조사해 ConvNet 과 Transformer 사이의 성능 격차를 해소하고 순수 ConvNet 을 더 발전시키고자 합니다.
3. Modernizing a ConvNet: a Roadmap
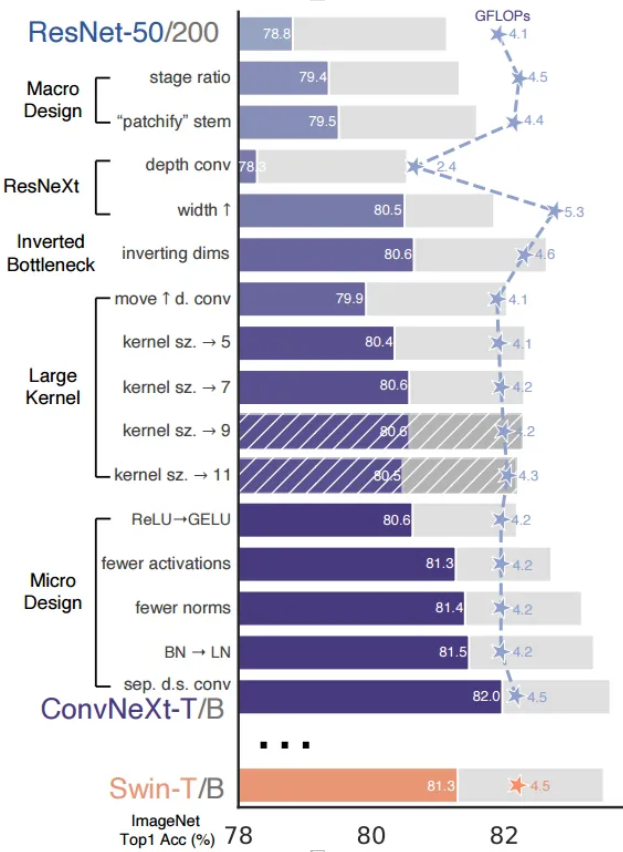
이 단락에서는 표준 ConvNet으로서 네트워크의 단순성을 유지하면서 Swin Transformer에서 다양한 설계 디자인들을 조사하고 이를 반영합니다.
논문에서는 이를 "네트워크 현대화" 라 하며, ResNet-50 부터 시작해 여러 기법들을 차레차례 적용하며 성능 및 Flops 를 비교합니다.
3.1. Training Techniques [76.1% → 78.8%]
DeiT 나 Swin Transfomer 와 유사한 학습 방법 사용하여 성능을 향상시킵니다.
- 90 -> 300 epochs
- AdamW
- Data augmentation (Mixup, Cutmix, RandAugment, Random Erasing, regularization, Label Smoothing 등)
3.2. Macro Design
Swin Transformer 의 macro design 을 분석하면, Swin Transformer 는 ConvNet 의 multi-stage design 을 사용합니다.
논문에서는 stage compute ratio 와 “stem cell” structure 를 관심을 가졌다고 합니다.
3.2.1 Changing stage compute ratio [78.8% → 79.4%]
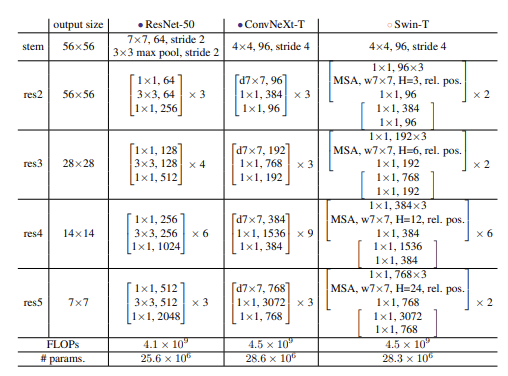
ResNet 의 stage 단계인 (3, 4, 6, 3) 은 경험적으로 설계 된 것이고, Swin Transformer Tiny 의 경우 (3, 3, 9, 3) 으로 비율이 1 : 1 : 3 : 1 이었고, large Swin 의 경우 1 : 1: 9 : 1 입니다.
Swin-T 의 디자인에 맞추어 ResNet Stage 당 Block 반복횟수를 조절하여 Swin-T 와 FLOPS 를 맞췄습니다.
- stage (3, 4, 6, 3) → (3, 3, 9, 3)
3.2.2 Changing stem to “Patchify” [79.4% → 79.5%]
이미지가 네트워크에 들어갈 때 처음 만나는 레이어를 stem 이라 합니다. 보통 적절한 feature map size 로 줄이기 위해 공격적으로 다운샘플링을 합니다.
ResNet 은 7x7 Convolutioin, stride=2, maxpool 을 사용하여 4배 다운샘플링 합니다. ViT 에서는 좀 더 공격적인 "패치화" 전략이 사용되어 큰 kernel size (14 or 16) 과 non-overlapping(비 중첩) convolution 을 사용합니다. Swin은 유사한 "패치화" 레이어를 사용하지만 아키텍처의 다단계 설계를 수용하기 위해 패치 크기가 4로 더 작습니다.
Swin 의 디자인에 맟주어 stem 을 4×4, stride 4 convolutional layer 로 바꿉니다.
- Stem layer: 7x7 Convolutioin, stride = 2 → 4x4 Convolution, stride=4 (non-overlapping)
3.3. ResNeXt-ify [79.5% → 80.5%]

바닐라 ResNet 에 비해 더 나은 Flops/Accurucy 상관관계를 가지는 ResNeXt 의 아이디어를 적용합니다.
핵심은 grouped convolution 으로, Convolution Filter 가 서로 다른 그룹으로 분리해서 계산합니다.
논문에서는 Group 수가 Channel 수와 같은 depthwise convolution 을 사용하는데, depthwise convolution 은 채널 단위로공간 차원의 정보만 혼합하여 작동하는 셀프 어텐션의 가중 합 연산과 유사하다고 합니다.
이를 통해 채널당 공간정보(height, width 차원을 의미하는 것 같습니다) 를 계산하게 되고, 효과적으로 Flops 를 줄이지만 accurcy 도 줄어들기 때문에 ResNeXt의 전략를 따라 채널 수를 Swin-T 와 같게 64 → 96 으로 변경하였다고 합니다.
이런 방법을 FLOP은 5.3G 가 늘어나고 정확도를 향상시켰습니다.
- depthwise convolution 적용, channel 수 64 → 96
3.4. Inverted Bottleneck [80.5% → 80.6%]

모든 Transformer Block에서 중요한 설계 중 하나는 inverted bottleneck 인데 ConvNets에서 사용되는 확장 비율 4의 inverted bottleneck design 와 비슷하다고 볼 수 있습니다.
(a) 는 ResNet Block 이고 (b) 가 새로 만든 inverted bottleneck입니다.
Inverted Bottleneck 으로 변경 시 depthwise convolution layer의 FLOP이 증가했음에도 불구하고 이러한 변경으로 인해 다운샘플링 residual blocks의 shortcut 1×1 convolution layer 에서 상당한 FLOPs 감소로 인해 전체 네트워크 FLOPs가 4.6G로 감소한다고 합니다.
- Bottleneck Design → Inverted Bottleneck Design
3.5. Large Kernel Sizes
Convolution 의 kernel size 가 클 경우, Recipted Field 가 커 성능향상에 유리하지만, 컴퓨팅 파워가 더 필요합니다. 초기 ConvNet 모델은 큰 kernel size 를 사용했지만, 이후 VGG 나 ResNet 같은 모델을 효율화를 위해 (3x3) 을 사용했습니다.
Swin Transformer 는 self-attention block 에 local window 를 재도입하는데, kernel size 가 3x3 이 아닌 7x7 을 사용합니다.
여기서는 ConvNet에 큰 kernel size의 convolution을 사용하는 것에 대해 다시 살펴본다고 합니다.
3.5.1 Moving up depthwise conv layer. [ → 79.9%]
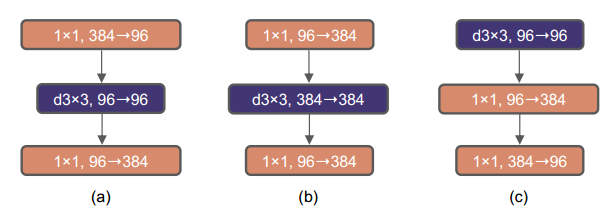
3x3 conv layer는 1x1 보다 계산량이 많고 비효율적인 MSA(large kernel Conv) 이기 때문에 의 위치를 트랜스포머 처럼 앞서 배치하여 계산량을 줄이고, 효율적인 1x1 Conv layer가 채널수를 늘리는 무거운 작업을 처리하게 합니다.
이 중간 단계에서는 FLOP이 4.1G로 감소하여 일시적으로 성능이 79.9%로 저하됩니다.
- b → c
3.5.2 Increasing the kernel size. [79.9% → 80.6%]
Convolution layer 의 kernel size 가 더 커질 수록 얻을 수 이점이 상당합니다. 논문에서는 3, 5, 7, 9, 11 등 여러 kernel size 로 실험하여 네트워크의 성능은 79.9%(3×3)에서 80.6%(7×7)로 증가하고 Flops 는 비슷하게 유지된 것을 확인하였습니다.
성능향상은 7x7 kernel size 에서 포화되어 kernel size 를 7x7 로 정했다고 합니다.
- MSA layere: 3x3 Convolution layer → 7x7 Convolution layer
3.6. Micro Design

여기서는 Activation Function 및 Normalization layer 에 대해 관찰합니다.
3.6.1 Replacing ReLU with GELU [80.6% → 80.6%]
Transfomer 구조를 쓰는 ViT 나 Swin 등의 모델은 Activation Function 으로 GELU 를 사용합니다.
ResNet 의 ReLU 를 GELU 로 대체한 결과 성능이 동일하다는 것을 발견했다고 합니다. ConvNet 에서도 GELU 를 쓸수있다는 결론을 내렸습니다.
- Activation Funtion: ReLU → GELU
3.6.2 Fewer activation functions. [80.6% → 81.3%]
ResNet Block 은 각 Conv layer 를 통과할때마다 Activation Function 을 사용합니다. Transformer 의 경우 Scaled-Dot Product Attention 연산 후 Feed-Forward Network 에서 한 번의 Activation Function 을 사용합니다.
Transformer 처럼 각 Block 마다 한 번의 GELU 를 사용하는 전략을 적용하여 성능 향상을 이끌어냈습니다.
- Block 당 3개 Activation Fuction → 1개 Activation Function(GELU)
3.6.3 Fewer normalization layers. [81.3% → 81.4%]
Transformer 는 Block 당 하나의 Normalization layer 를 사용하므로 똑같이 하나의 Normalization layer 를 사용하는 것을 적용했다고 합니다.
- Block 당 3개 Normalization layer → 1개 Normalization layer
3.6.4 Substituting BN with LN. [81.4% → 81.5%]
BatchNorm은 수렴을 개선하고 과적합을 줄이기 때문에 ConvNets에서 필수적인 구성 요소로 널리 사용되었지만, 단점이 존재합니다.
LayerNorm 은 다양한 작업에서 우수한 성능을 발휘하는 Transformer 에 사용되어 왔습니다.
원래 ResNet 에서 BN 을 LN 으로 대체하면 성능 저하가 일어나지만, 많은 부분을 수정한 ResNet 아키텍쳐에 LN 을 적용할 시 성능이 약간 향상되었다고 합니다.
- Batch Normalization → Layer Normalization
3.6.5 Separate downsampling layers.[81.5% → 82.0%]
ResNet 은 Downsampling 을 각 Stage 시작 시 3x3 kernel size, Stride=2 인 Convolution layer 를 이용합니다. Swin Transformer 는 각 Stage 사이에 별도의 Downsampling layer 를 사용합니다.
Swin Transformer 와 유사하게 별도의 2x2 kernel size, stride=2 인 Downsampling layer 를 추가하고, 학습 시 발산되는 문제를 해결하기 위해 Normalization Layer 를 추가하여 성능을 향상시켰다고 합니다. Normalization Layer 는 마지막 Global Avarage Pooling 이후에도 사용했다고 합니다.
이 방법을 적용하여 Swin-T 정확도 81.3% 을 큰 폭으로 뛰어넘었다고 합니다.
- DonwSampling: Stage 첫 Block 에서 3x3, Stride=2 Conv layer → Stage 이후 별도의 2x2, Stride=2 Conv layer
3.7 Closing Remark
위 과정을 통해 Swin-T 와 비슷한 Flops, 파라메터, 처리속도,메모리사용량을 가지면서 Swin-T의 성능을 뛰어넘는 ConvNeXt 를 만들었습니다. 이는 새로운 발견을 한 것이 아니고 기존에 연구된 것들을 종합한 것이라고 합니다.
4. Empirical Evaluations on ImageNet

'DeepLeaning > 이론' 카테고리의 다른 글
| [논문리뷰]Deep Residual Learning for Image Recognition(2015), ResNet 리뷰 (0) | 2023.07.17 |
|---|---|
| Transformer 와 Attention (2) (0) | 2023.06.29 |
| Transformer 와 Attention (1) (0) | 2023.06.29 |







